Chapter 3
Issues in Personality Assessment
Modified: 2022-06-26 12:59 pm
Everybody assess other's personalities. Personality psychologists assess personality scientifically using a variety of methods. Those methods must be reliable and valid. Assuring reliability is vital for valid assessment methods. Validity, in turn, requires construct validation using criterion, convergent, and discriminant validity. Development of assessments follows two approaches: rational and empirical.
- Learning Objectives:
- 3.1 Report three techniques used to access information about personality
- 3.2 Distinguish between the discerment of the three kinds of reliability
- 3.3 Analyze the issue of validity in assessment
- 3.4 Relate the logic behind the theoretical and empirical approaches to the development of assessment devices
- 3.5 Analyze the importance of investing in effort in creating and improving tests of personality
- 3.1 Sources of Information
(p. 20)
- Assessment is the general term for the measuring of personality
- Informal assessments are common but can be misleading
- There are two sources: your own personal experience and other people react to the world
- Psychologists, you will learn, use the word more abstractly
- 3.1.1 Observer Ratings
- When others assess personality those are observer ratings. Those can include:
- Interviews
- Watching other's actions
- Ratings by other's who know the person being studied
- Rating the objects others own or buy
- Box 3.1 What Does Your Stuff Say about You? (p.21)
- Sam Gosling: "portray and betray" he and his group study:
- Identity claims
- Photos, awards, and other objects displayed
- Feeling regulators
- Items that help set a mood: happy photos, sooting music
- Behavioral residue
- Physical traces of our personality
- Trash is a prominent one (police will often investigate a person's trash)
- 3.1.2 Self-Reports
- An organized kind of introspection
- Usually done with pre-written items
- Are done in a variety of formats: T-F or Likert scales
- Can be created for one personality dimension or several
- 3.1.3 Implicit Assessment
- Ask person to make judgments (me/not me for example) indirectly
- The Implicit Association Test
- You may take the Harvard Implicit Association Test by clicking HERE
- There are many ways to assess personality and all require two things:
- a sample of behavior (actions, physiological measures, or answering questions)
- someone to use the behavior sample to learn about an aspect of personality
- 3.1.4 Subjective versus Objective Measures
- Personality measures can be subjective or objective
- Subjective measures:
- Require an interpretation (the interviewee appeared nervous)
- Objective measures
- Require no interpretation (the interviewee touched his nose 22 time in five minutes)
- Self-reports are vulnerable to being subjective
- 3.2 Reliability of Measurement (p. 22)
- A reliable measurement:
- Will show the same value when repeated
- Is consistent
- Low reliable measures:
- Are inconsistent
- More subject to randomness or error
- Repeating measurements makes them more reliable
- Reliability issues are seen in many different places
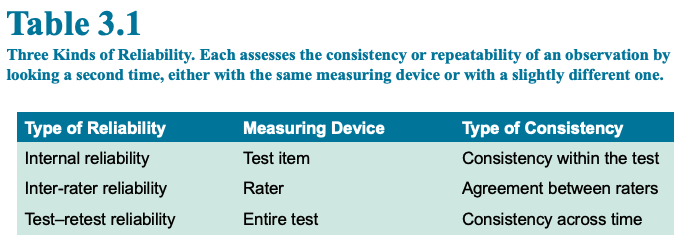
- 3.2.1 Internal Consistency
- Use more than one item as a "measuring device"
- The more items, the more likely they are to cancel out error from each item, that is:
- Internal Reliability or internal consistency
- Split-half reliability is an easy way to determine internal reliability
- It is when researchers examine the correlation between two halves of a measure
- Often, the odd numbered questions are correlated with the even numbered questions
- Box 3.2 A New Approach to Assessment: Item Response Theory (p. 23)
- In Item Response Theory:
- Response curves are created for every item
- Response choices are analyzed and if two choices have similar response curves (e.g., "often" and "sometimes") they may be combined
- The "difficulty" of individual items is analyzed and items that are more extreme ("I get panicky" vs "I worry") are selected for use
- Item Response Theory has revealed closer than previously realized overlap of normal vs abnormal personality scores.
- 3.2.2 Inter-Rater Reliability
- Personality is also measured by others, not self-reports
- Each rater can be thought of as an individual measuring device
- Researchers should look for strong correlations between raters observing the same event. This is called:
- Interater reliability is high when raters are highly trained and experienced
- One example is Olympic Swim Judges
- In some athletic competitions (gymnastics, for example) the highest and lowest rating are discarded
- 3.2.3 Stability across Time
- Because personality is expected to be stable, ratings should be similar over time
- Test-retest reliability measures this aspect of reliability
- Table 3.1 (below) shows the three types of reliability
- 3.3 Validity of Measurement (p. 24)
- Validity is another important aspect of psychological measurement
- The basic issue is: Are you measuring the phenomenon you believe you are measuring?
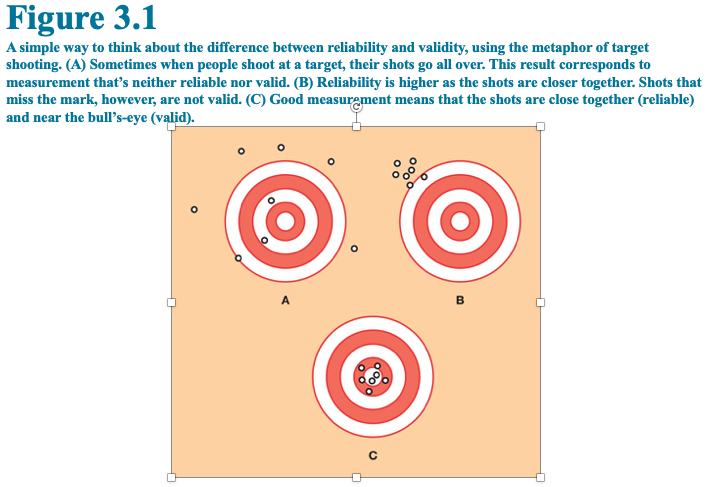
- Figure 3.1 (below) uses marksmanship to distinguish between reliability and validity
- In A there is neither reliability or validity
- In B there is reliability, the firearm shoots a tight group but not at the bullseye (the shooter was aiming at the bullseye, fyi)
- In C there is reliability and validity because the shots are tightly grouped and they cluster around the bullseye.
- FYI: that all of the shots do not hit the bullseye exactly illustrates the concept of error
- Deciding if validity has been achieved is not easy
- Psychologists distinguish between:
- Conceptual definitions
- Basically, dictionary definitions
- Operant definitions
- Definitions based upon the operations that produce them
- Example, the word "hunger"
- Conceptual definition: a feeling of discomfort or weakness caused by lack of food, coupled with the desire to eat. (from Google's Oxford Languages)
- Operational definition: not having eaten for X hours
- Notice that these two definitions agree closely but that the operational definition may be experimentally manipulated (within physiological limits)
- Meaning I could define "hungry" as 6 hours of food deprivation and "hungrier" as 12 hours of food deprivation
- 3.31 Construct Validity
- Construct validity is when the measure reflects the construct (see hunger example above). Food deprivation and hunger reflect each other.
- 3.32 Criterion Validity
- Does the measure chosen actually reflect the construct validity?
- Criterion validity should support construct validity
- That support may come from behavioral measures or professional judgment
- See Figure 3.1 and ask yourself is that person a good shot?
- In A, you cannot answer the question. It could be the firearm or the shooter that is spraying bullets at random
- In B, you can say that the person is a good shot, but the firearm's sights need adjustment
- In C, you can say that the shooter is accurate and the firearm's sights are adjusted to point of aim
- Notice that in this case the accuracy of the shooter was the criterion
- Caution!
- Too often, researchers fail to adequately choose a proper criterion. So, any results they obtain are meaningless
- 3.3.3 Convergent Validity
- Once a criterion is chosen then other, similar measures should correlate strongly with it.
- Looking at Figure 3.1 (above) again you might find that the shooter's hand cannot hold steady. That would be a negative correlation (steadiness vs accuracy)
- Or, you might find that visual acuity is correlated with accuracy
- Both of those are examples of convergent validity
- 3.3.4 Discriminant Validity
- Are there measures that do not affect the conceptual definition of the construct?
- It is important to identify those in order to deal with the third variable problem discussed in chapter 2
- Let's go back to Figure 3.1 (above). Suppose that previous research showed that there was not correlation between IQ and accurate marksmanship
- In that case, no one could invoke IQ as a third variable
- However, researchers must always be alert that a possible third variable exists, one that they have not identified.
- 3.3.5 Face Validity
- Face validity is less important than other types of validity but it should be examined, regardless
- When people judge a measure as looking right, that is one way to understand it
- So, using Figure 3.1 (above) again, questions about firearms, bullets, and targets would have high face validity in assessing shooting accuracy
- 3.3.6 Culture and Validity
- Cultural differences exist
- So, does a personality test designed in one culture give the same answers in another culture? It depends:
- Does the psychological construct in question have the same meaning in both cultures?
- Do the cultures tested interpret the items on the personality measure in the same way?
- Translating personality measures from one language to another is also difficult because of ideomatic and metaphors
- 3.3.7 Response Sets and Loss of Validity
- Most people have built in biases (response sets) that might affect how they answer personality measures. Two of those are:
- Acquiescence
- Most people when confronted with a binary choice (e.g., "yes" vs "no" or "agree" vs "disagree" will choose "yes" or "agree"
- So, personality assessors often write questions using positive and negative phrasing to counteract the tendency to give positive answers
- Social desirability
- Many people like to portray themselves in a good light
- Here, personality assessors write questions minimizing social desirability
- 3.4 Two Rationales behind the Development of Assessment Devices
(p. 28)
- Here, the issues is to understand what personality qualities to measure in the first place.
- 3.41. Rational or Theoretical Approach
- In the rational or theoretical approach theory dominates
- Psychologists develop a theory and then seek to create a valid and reliable measure of one or more constructs
- These tools have strong face validity and form the majority of personality assessments in use today.
- 3.4.2 Empirical Approaches
- This approach works backward from most
- First a people are asked a large number of questions
- The idea is to find questions that one group answers consistently while the other does not. This is called: criterion keying
- The MMPI is a good example of this method
- Its questions were selected from two populations: normal people and psychiatric patients
- The criterion was to detect abnormality
- However, recent critiques have centered around the definition of abnormality
- This approach will be reviewed more deeply in chapter 4
- 3.5 Never-Ending Search for Better Assessment (p. 29)
- Personality assessment is a never ending project
- Tests are revised and restandardized often using many research studies
- The popular tests found in magazines, newspapers, and web pages typically do not rise to the level of a properly created psychological assessment. Most likely, no one as ever assessed the reliability or validity of such popularly available tests.
- Summary
(p. 29)
- Everyone conducts informal personality assessments
- Personality psychologists develop formal personality assessments and they use:
- Observer ratings
- Self-reports
- Implicit assessment
- Their tests may be objective or subjective.
- Subjective tests require interpretation
- Personality tests should:
- Be reliable
- Be valid
- Constuct validation is assured by:
- criterion validity
- convergent validity
- discriminant validity
- face validity is not usually important
- Assessment device development can be:
- Rational
- Most assessments fall into this category
- These are based on theory
- Empirical
- These use large amounts of data to distinguish groups from each other
- The MMPI was created this way using criterion keying
- Points to Remember
- Assessment (measurement of personality) is something that people constantly do informally. Psychologists formalize this process into several distinct techniques.
- Observer ratings are made by someone other than the person being rated—an interviewer, someone who watches, or someone who knows the people well enough to make ratings of what they are like. Observer ratings often are somewhat subjective, involving interpretations of the person’s behavior.
- Self-reports are made by the people being assessed about themselves. Self-reports can be single scales or multiscale inventories.
- Implicit assessment is measuring patterns of associations within the self that are not open to introspection. Assessment devices can be subjective or objective. Objective techniques require no interpretation as the assessment is made. Subjective techniques involve some sort of interpretation as an intrinsic part of the measure.
- One issue for all assessment is reliability (the reproducibility of the measurement). Reliability is determined by checking one measurement against another (or several others).
- Self-report scales usually have many items (each a measurement), leading to indices of internal reliability, or internal consistency.
- Observer judgments are checked by inter-rater reliability. Test–retest reliability assesses the reproducibility of the measure over time. In all cases, high correlation among measures means good reliability.
- Another important issue is validity (whether what you’re measuring is what you want to measure).
- The attempt to determine whether the operational definition (the assessment device) matches the concept you set out to measure is called construct validation.
- Contributors to construct validity are evidence of criterion, convergent, and discriminant validity.
- Face validity is not usually taken as an important element of construct validity.
- Validity is threatened by the fact that people have response sets (acquiescence and social desirability) that bias their responses.
- Development of assessment devices proceeds along one of two paths.
- The rational path uses a theory to decide what should be measured and then figures out the best way to measure it. Most assessment devices developed this way.
- The empirical path involves using data to determine what items should be in a scale.
- The MMPI was developed this way, using a technique called criterion keying, in which the test developers let people’s responses tell them which items to use. Test items that members of a diagnostic category answered differently from other people were retained.
KEY TERMS
- Acquiescence: The response set of tending to say “yes” (to agree) in response to any question.
- Assessment: The measuring of personality.
- Construct validity: The accuracy with which a measure reflects the underlying concept.
- Convergent validity: The degree to which a measure relates to other characteristics that are conceptually similar to what it’s supposed to assess.
- Criterion keying: The developing of a test by seeing which items distinguish between groups.
- Criterion validity: The degree to which the measure correlates with a separate criterion reflecting the same concept.
- Discriminant validity: The degree to which a scale does not measure unintended qualities.
- Empirical approach (to scale development): The use of data instead of theory to decide what should go into the measure.
- Error: Random influences that are incorporated in measurements.
- Face validity: The scale “looks” as if it measures what it’s supposed to measure.
- Implicit assessment: Measuring associations between the sense of self and aspects of personality that are implicit (hard to introspect about).
- Internal reliability (internal consistency): Agreement among responses made to the items of a measure.
- Inter-rater reliability: The degree of agreement between observers of the same events.
- Inventory: A personality test measuring several aspects of personality on distinct subscales.
- Objective measure: A measure that incorporates no interpretation.
- Observer ratings: An assessment in which someone else produces information about the person being assessed.
- Operational definition: The defining of a concept by the concrete events through which it is measured (or manipulated).
- Predictive validity: The degree to which the measure predicts other variables it should predict.
- Rational approach (to scale development): The use of a theory to decide what you want to measure, then deciding how to measure it.
- Reliability: Consistency across repeated measurements.
- Response set: A biased orientation to answering.
- Self-report: An assessment in which people make ratings pertaining to themselves.
- Social desirability: The response set of tending to portray oneself favorably.
- Split-half reliability: Assessing internal consistency among responses to items of a measure by splitting the items into halves, then correlating them.
- Subjective measure: A measure incorporating personal interpretation.
- Test-retest reliability: The stability of measurements across time.
- Theoretical approach: See Rational approach.
- Validity: The degree to which a measure actually measures what it is intended to measure
Back to Main Page